
The machinery for viral replication and transcription is translated from particular sections of the severe acute respiratory syndrome coronavirus 2 (SARS-CoV-2) genome, open reading frames 1a and 1b (ORF1a and ORF1b). Sixteen non-structural proteins (NSP) are produced upon translation. Of these, some appear to be highly conserved across coronavirus lineages due to the vital and essential role these proteins play in replication, making the occurrence of successful and distinct mutants rare. In a research paper recently uploaded to the preprint server bioRxiv* by Newman et al. (March 15th, 2021) the structure and role of one such protein: NSP13, is investigated, with two appealingly druggable targets being identified, possibly opening a new route towards a novel SARS-CoV-2 antiviral agent.
What is NSP13?
NSP13 is a 67 kDa helicase protein, helicases being a class of enzymes that separate nucleic acid strands and thus are directly involved in many cellular processes such as replication, transcription, and translation. NSP13 belongs to the helicase superfamily 1B, this further categorization indicating that the protein does not form a ring structure, as is the case with all known RNA helicases in eukaryotes, though some ring-forming helicases have been found in viruses, and that the enzyme performs translocation in the 5’-3’ direction.
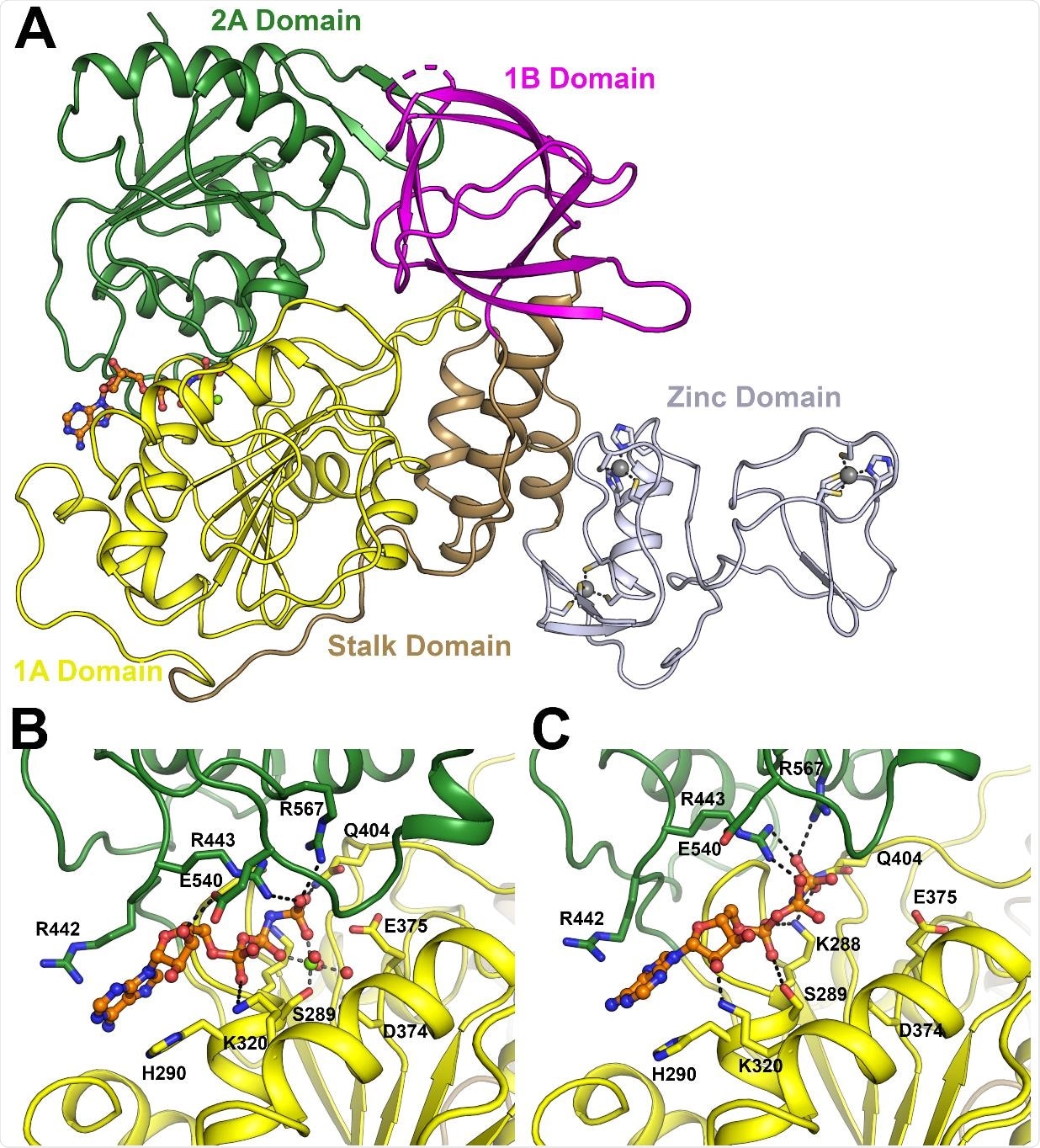
NSP13 contains 5 domains: an N-terminal zinc-binding domain, a helical stalk, a beta-barrel, and two binding domains that make contact with the nucleotides. The protein is also structurally very similar in both MERS-CoV and SARS-CoV-1, differing by only a single amino acid in the case of the latter, and so has been proposed as a promising target for antiviral drugs. Some preliminary drug development has already taken place towards drugging this particular protein target, given its strongly conserved presence even in more distantly related viruses still. However, the precise structure of this protein has not yet been entirely elucidated for SARS-CoV-2. X-ray crystallographic structures are the gold standard in determining protein conformation in various in situ modes, accounting for when bound with target nucleotides and when part of the transcription supercluster of proteins. The group uncovered two likely binding pockets in this manner, and further performed a fragment screening of the protein to test the ligandability, providing a starting structure upon which the rational design of drugs can be based.
The crystal structure of NSP13
Three conformations of the proteins were examined: the APO form, when free and not bound with the associated enzyme cofactor proteins; the phosphate bound form, which is active; and the nucleotide bound form, representative of when engaged in enzymatic activity. In each case, the chains were noted to be similar to as described previously for NSP13 in related organisms. However, while the chains were of similar sequence, the overall conformational structure was found to differ in some regions by as much as 3 Å, attributed to the flexible zinc-binding domain and nucleotide-binding domains.
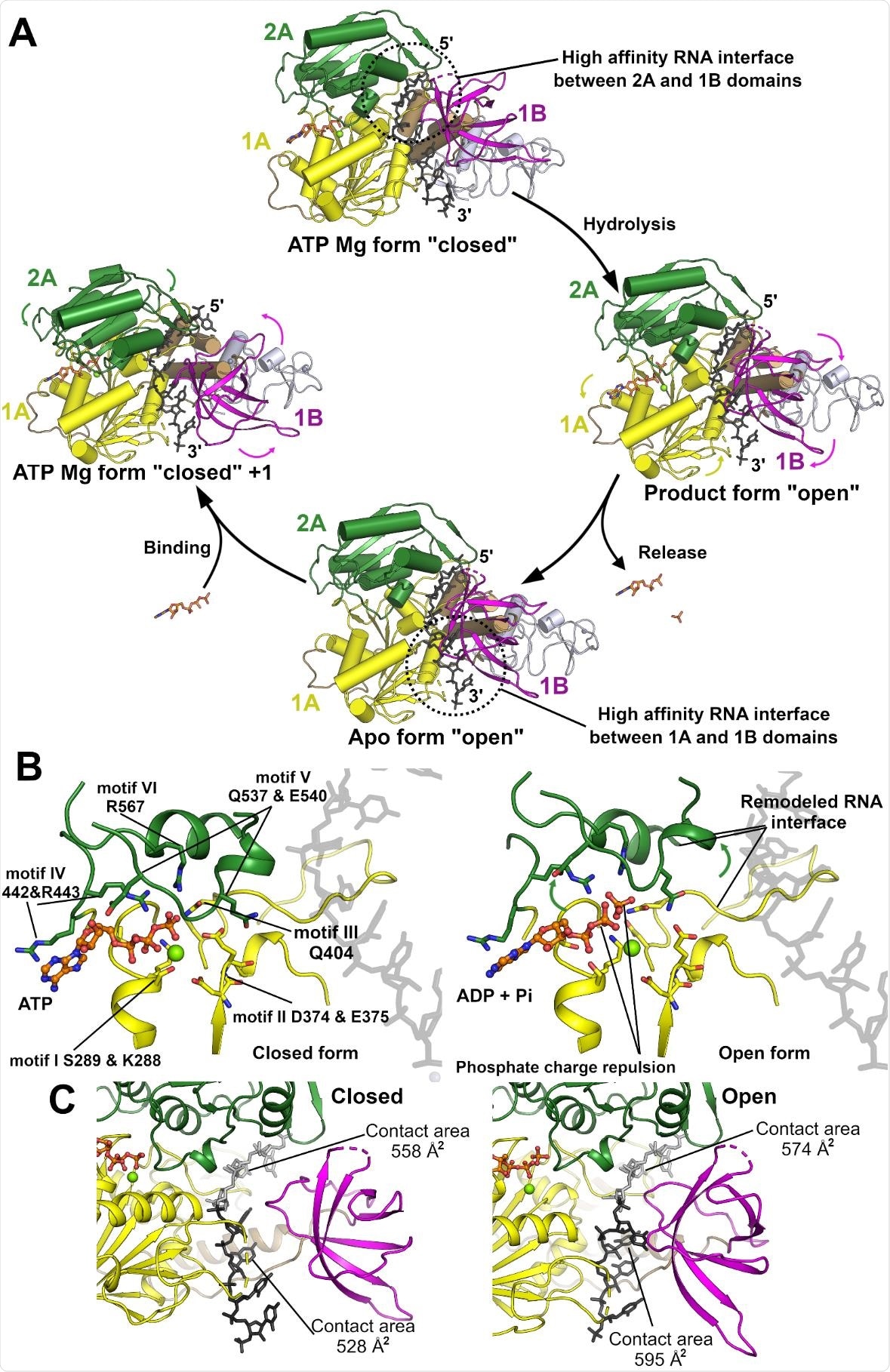
Specific changes in the nucleotide-binding sites could be observed as the protein transitioned between open and closed states, to which the group ascribe the translocation mechanism of the protein along the nucleotide chain. When in the closed conformation, RNA binds with the protein preferentially through one of the two binding domains, with the weaker bond towards the 3’ end. ATP hydrolysis then triggers the conformational change to the open state, reversing the affinities and shifting the protein along the chain by one nucleotide.
Crystallographic fragment screening
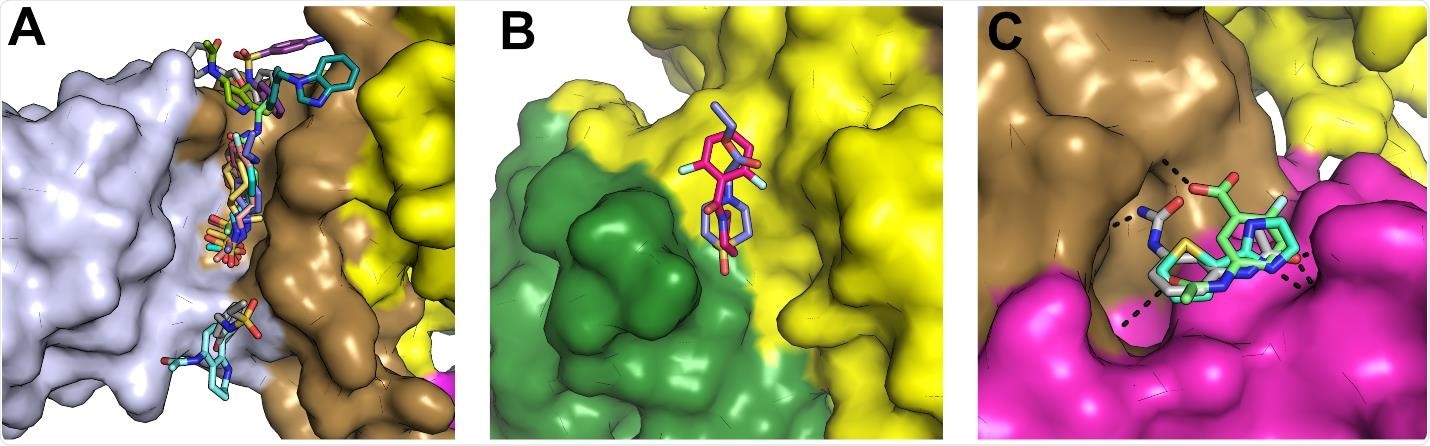
The phosphate-bound form of NSP13 was crystallized, and 648 crystals individually soaked in a library of chemical fragments. X-ray analysis was then performed, and any bound ligands were identified. 65 fragments were identified to bind to various sites of the protein, 15 of which overlapped the ATP ribose moiety. Several others were located close to the RNA/DNA binding pocket and would be expected to block interaction with the protein. A small number of additional ligands were expected to bind the zinc domain of the protein with the stalk domain, disallowing the conformational changes necessary to engage in nucleotide bonding.
Further computational analysis of target sites was performed, in particular, noting the 5’-RNA binding pocket as eminently druggable due to the hydrophobic environment, good accessibility when the protein is in the open conformation, and high conservation across other coronaviruses.
*Important Notice
bioRxiv publishes preliminary scientific reports that are not peer-reviewed and, therefore, should not be regarded as conclusive, guide clinical practice/health-related behavior, or treated as established information.
- Structure, Mechanism and Crystallographic fragment screening of the SARS-CoV-2 NSP13 helicase. Joseph A Newman, Alice Douangamath, Setayesh Yazdani, Yuliana Yosaatmadja, Anthony Aimon, José Brandão-Neto, Louise Dunnett, Tyler Gorrie-stone, Rachel Skyner, Daren Fearon, Matthieu Schapira, Frank von Delft, Opher Gileadi. bioRxiv. 2021.03.15.435326; doi: https://doi.org/10.1101/2021.03.15.435326, https://www.biorxiv.org/content/10.1101/2021.03.15.435326v1
Posted in: Medical Research News | Disease/Infection News
Tags: Amino Acid, Coronavirus, Coronavirus Disease COVID-19, DNA, Drugs, Enzyme, Eukaryotes, Genome, Helicase, MERS-CoV, Nucleic Acid, Nucleotide, Nucleotides, Protein, Research, Respiratory, RNA, SARS, SARS-CoV-2, Severe Acute Respiratory, Severe Acute Respiratory Syndrome, Syndrome, Transcription, Translation, X-Ray, Zinc

Written by
Michael Greenwood
Michael graduated from Manchester Metropolitan University with a B.Sc. in Chemistry in 2014, where he majored in organic, inorganic, physical and analytical chemistry. He is currently completing a Ph.D. on the design and production of gold nanoparticles able to act as multimodal anticancer agents, being both drug delivery platforms and radiation dose enhancers.
Source: Read Full Article